一,项目背景
公司业务线扩张后,服务器节点从最初的 30 台增长到 200+ 台,横跨阿里云、腾讯云和自建机房三个环境。原有的 Zabbix 单点部署已无法满足需求——告警延迟严重(最长达 15 分钟)、规则混乱(累计 800+ 条未经梳理的告警项)、多环境数据割裂,运维团队每周需要花费大量时间处理误报和漏报。
核心痛点总结如下:
- 告警风暴:一次网络抖动触发 200+ 条关联告警,真正需要关注的不到 5 条
- 环境割裂:三套监控系统各自为政,没有统一视图
- 阈值不合理:大量告警使用默认阈值,导致"狼来了"效应
- 缺乏可观测性:出了问题只知道"CPU 高了",无法快速定位根因
二、方案设计
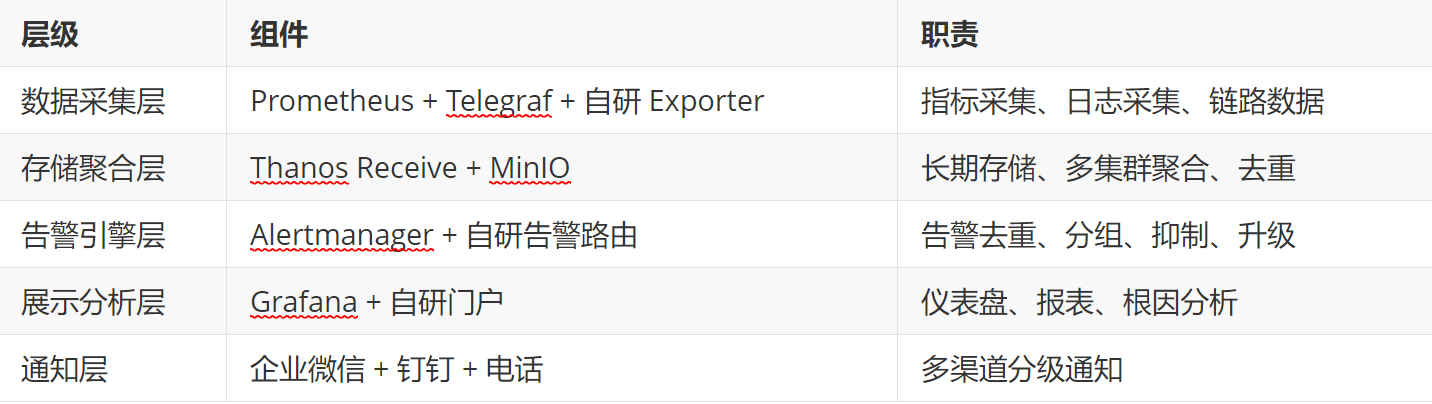
2.1 整体架构
- 采用 Prometheus + Thanos + Grafana + Alertmanager 为核心技术栈,构建统一可观测平台。架构分层如下:
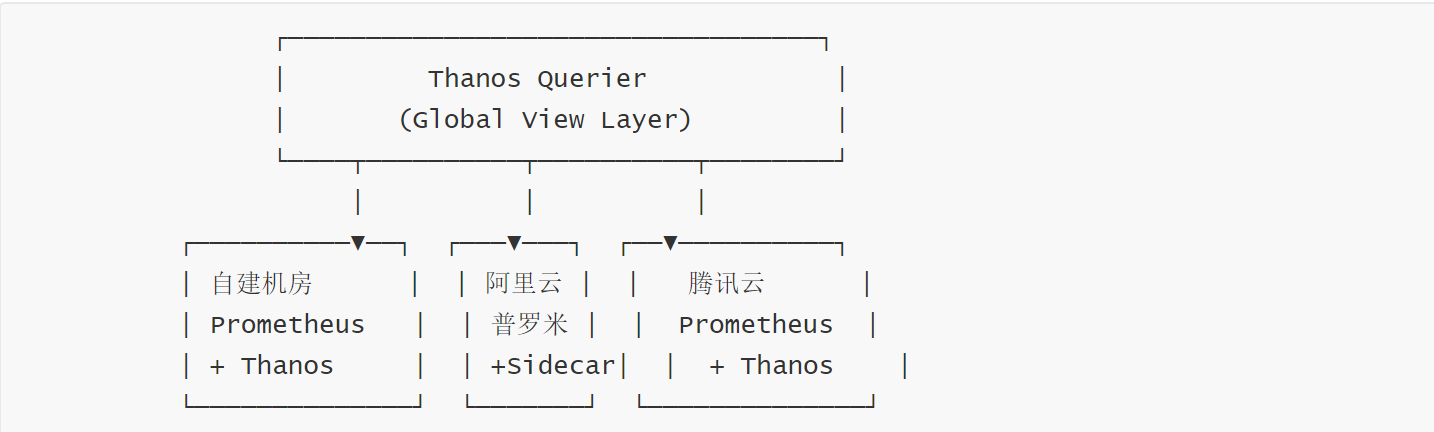
2.2 跨环境采集方案
- 不同环境采用不同的部署策略:
- 自建机房:Prometheus 以 StatefulSet 方式部署在 K8s 集群内,通过 Node Exporter + cAdvisor 覆盖节点和容器指标。针对非容器化遗留应用,部署 Telegraf 代理采集。
- 阿里云:Prometheus 直接拉取云监控 API(ECS、RDS、SLB、Redis 等),避免重复部署 Agent。关键指标通过企业级 Prometheus 实例做双路备份。
- 腾讯云:同理对接云 API,并通过内网专线将指标推送到 Thanos Receive 统一存储。
2.3 告警治理策略
- 告警治理是本次项目的核心难点。我们制定了四个关键策略:
- ① 告警分级(P0 ~ P3)
- P0(紧急):核心业务不可用、数据库宕机。电话 + 钉钉 + 企微,5 分钟内未响应自动升级到 Leader
- P1(严重):部分服务降级、响应延迟超阈值 2 倍。钉钉 + 企微,15 分钟升级
- P2(警告):磁盘 80%、内存 85%、连接数接近上限。仅企微通知
- P3(通知):证书到期提醒、资源趋势预警。邮件日报汇总
- ② 告警抑制(Inhibition)
- 配置 Alertmanager 抑制规则,例如:交换机宕机时,抑制该交换机下所有主机的网络不可达告警,避免告警风暴。

- ③ 告警聚合(Grouping)
- 将同一时间窗口内、同一业务线、同一告警类型的告警合并为一条通知,携带详细列表在附件中。
- ④ 告警静默(Silence)
- 与 CMDB 联动的维护窗口机制:设备进入维护状态时,关联告警自动静默,维护结束后自动恢复。
三、实施过程
阶段一:基础搭建(第 1-2 周)
- 完成 Prometheus + Thanos + Grafana 核心组件部署,覆盖自建机房所有节点的基础指标(CPU、内存、磁盘、网络、进程)。
- 关键步骤:
- 使用 Prometheus Operator 在 K8s 集群中部署,简化配置管理
- Thanos Sidecar 接入 S3 兼容对象存储(MinIO),实现长期存储和跨集群查询
- Grafana 接入统一 LDAP 认证,权限按团队划分
阶段二:告警迁移(第 3-4 周)
- 梳理原有的 800+ 条 Zabbix 告警规则,经过三轮评审后精简为 120 条 Prometheus 告警规则。精简原则:
- 同类合并:多个相似阈值规则合并为一条带标签的规则
- 去除无效:历史数据显示 30 天内从未触发的规则直接下线
- 业务对齐:与各业务负责人确认告警阈值和响应 SLA
- 同时配置 Alertmanager 的分组、抑制和通知路由规则,接入企业微信和钉钉 Webhook。
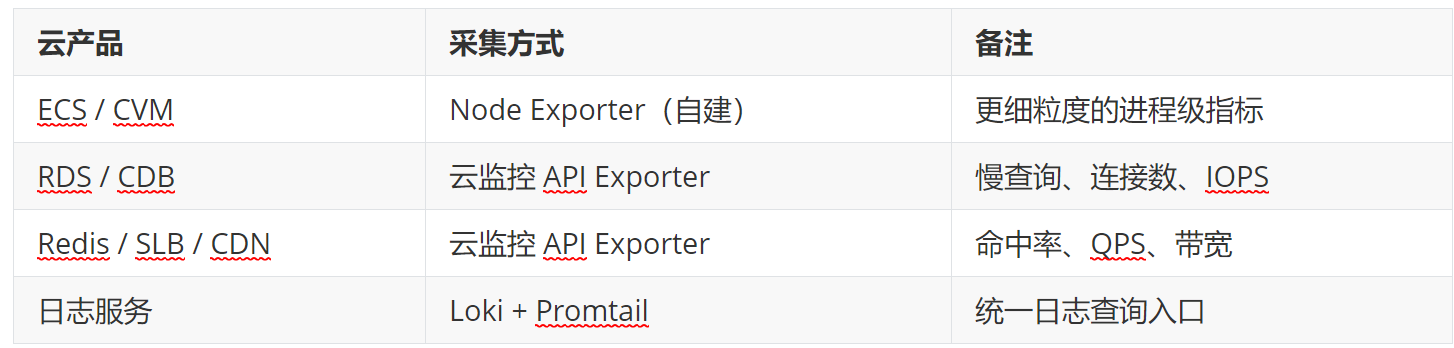
阶段三:多环境接入(第 5-6 周)
- 将阿里云和腾讯云的云资源指标接入统一平台。针对云产品的 Exporter 选型:
阶段四:优化与推广(第 7-8 周)
- Grafana 仪表盘模板化:每个业务线自动生成标准仪表盘
- 告警分时段规则:业务高峰期与低峰期使用不同阈值
- 编写运维手册:告警处理 SOP,每个告警附带处理指引链接
- 全公司推广培训:组织 3 次培训覆盖所有研发和运维团队
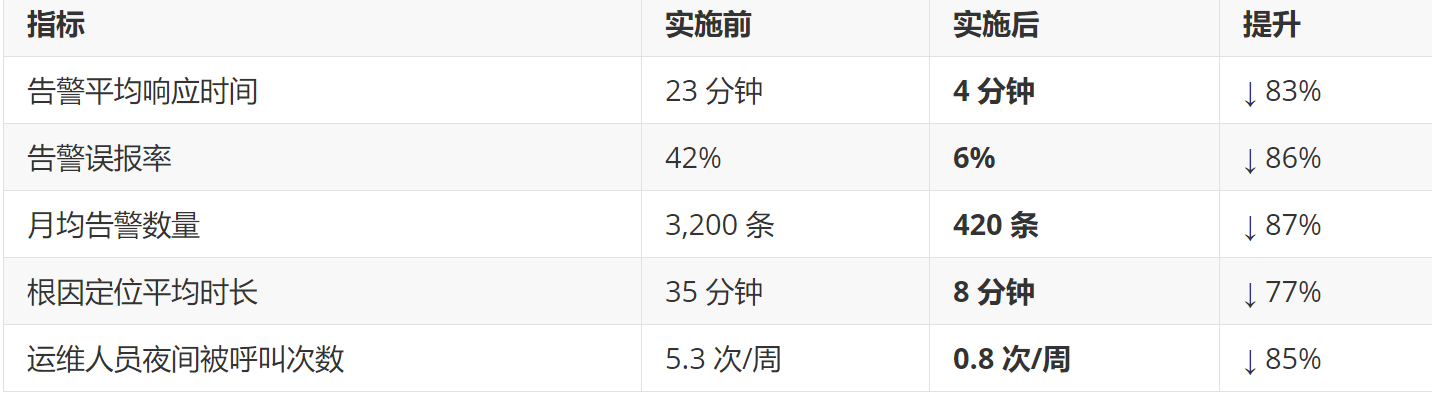
四、效果与收益
五、经验总结
1.告警治理比工具选型更重要:工具只是手段,真正降低运维负担的是告警梳理、分级和抑制策略。花在梳理 800+ 条告警上的时间比部署 Prometheus 本身多 3 倍。
2.先做加法,再做减法:阶段一我们故意采了 50+ 个指标维度,一个月后根据实际查询频率将采集量收敛到 25 个核心指标,避免存储膨胀。
3.自研 Exporter 解决长尾问题:标准 Exporter 无法覆盖部分遗留系统和业务指标,投入约 3 人天开发了两个自定义 Exporter,解决了关键盲区。
4.CMDB 联动是告警自动化的基础:告警与 CMDB 打通后才能实现维护窗口自动静默、告警责任人自动路由、资产变更同步等功能。
5.可视化降低认知负荷:好的仪表盘不只是"好看",而是能让值班人员 3 秒内判断当前系统是否健康。我们投入了大量精力打磨 Grafana 面板的布局和颜色语义。