摘要:随着企业数字化转型深入,IT系统架构从传统单体架构全面转向云原生、微服务、容器化架构,业务对IT系统的高可用、高并发、低延时要求持续提升,传统人工运维模式效率低、容错率差、响应滞后的弊端彻底凸显。本文结合一线运维实战经验,从现代运维架构迭代、核心运维工作难点、常见故障排查方案、自动化运维落地实践及运维安全保障五个维度,系统讲解新时代IT运维技术体系,为企业运维团队降本增效、保障业务稳定运行提供可落地的技术方案。
关键词:IT运维;自动化运维;故障排查;云原生;系统稳定性
IT运维是企业数字化系统稳定运行的核心基石,贯穿服务器、网络、数据库、应用程序、存储设备等全IT基础设施的日常管理、监控、故障处理、优化升级全流程。早期IT运维以“被动救火”为核心模式,主要依靠运维人员人工巡检、故障事后排查,适配传统物理服务器、单体应用架构。
当前,企业IT架构已全面升级,云计算、Docker容器、K8s编排、微服务、分布式数据库成为主流,IT基础设施规模成倍扩大,服务调用链路愈发复杂,业务秒级中断都会造成企业直接经济损失。在此背景下,现代IT运维彻底转向主动预防、自动化运维、智能化监控、全链路保障的新模式,运维工作从基础设备维护升级为业务稳定性、资源利用率、运维成本的综合性管控。
目前多数中小企业运维普遍存在三大痛点:一是监控体系不完善,故障发现滞后,无法实现事前预警;二是人工操作占比过高,重复部署、巡检、备份工作耗时费力,人为操作失误率高;三是故障排查无标准化流程,复杂链路故障定位缓慢,业务恢复周期长。本文针对以上痛点,结合实战场景给出全套优化方案。
现代标准化IT运维体系分为基础设施运维、应用运维、数据运维、安全运维、自动化运维五大核心模块,各模块相互协同,构成全维度运维保障体系,整体架构逻辑清晰、权责明确,适配云原生时代运维需求。
1. 基础设施运维:作为运维底层基础,涵盖物理服务器、云服务器、网络设备(交换机、路由器、防火墙)、存储设备、机房环境等资源的日常管理,主要工作包括设备上架、系统安装、资源扩容、网络调试、硬件故障排查、机房巡检等,保障底层硬件和基础环境稳定运行。
2. 应用运维:聚焦业务应用层,针对微服务、Web应用、接口服务、小程序后台等业务系统,负责应用部署、版本更新、日志排查、性能优化、服务启停、兼容性适配,是直接保障业务可用的核心模块。
3. 数据运维:核心围绕MySQL、Redis、MongoDB等数据库,完成数据备份、恢复、读写分离配置、索引优化、慢查询排查、数据安全管控,避免数据丢失、数据错乱、数据库性能瓶颈引发的业务故障。
4. 安全运维:兼顾系统安全与业务安全,包括漏洞扫描、补丁更新、权限管控、访问白名单配置、攻击防护、日志审计、安全合规自查,抵御黑客攻击、越权访问、数据泄露等安全风险。
5. 自动化运维:新时代运维核心升级模块,通过脚本、工具、平台替代人工重复操作,实现自动化部署、自动化巡检、自动化备份、故障自动告警、自动恢复,大幅提升运维效率。
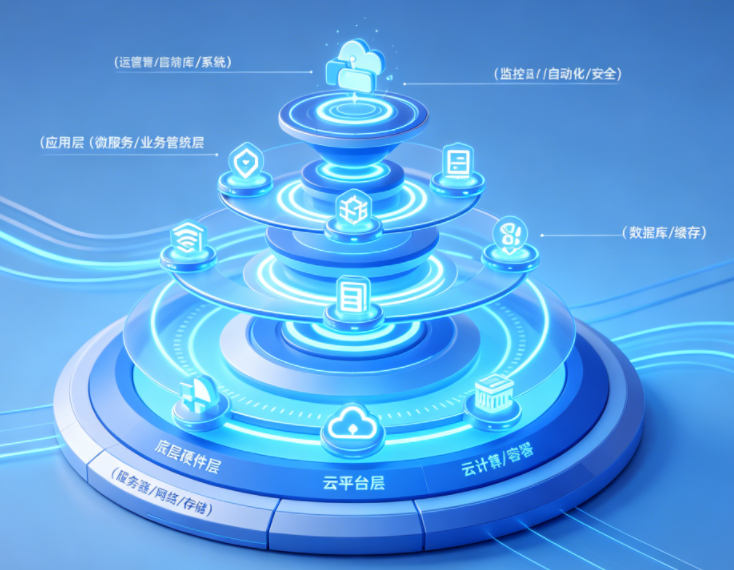
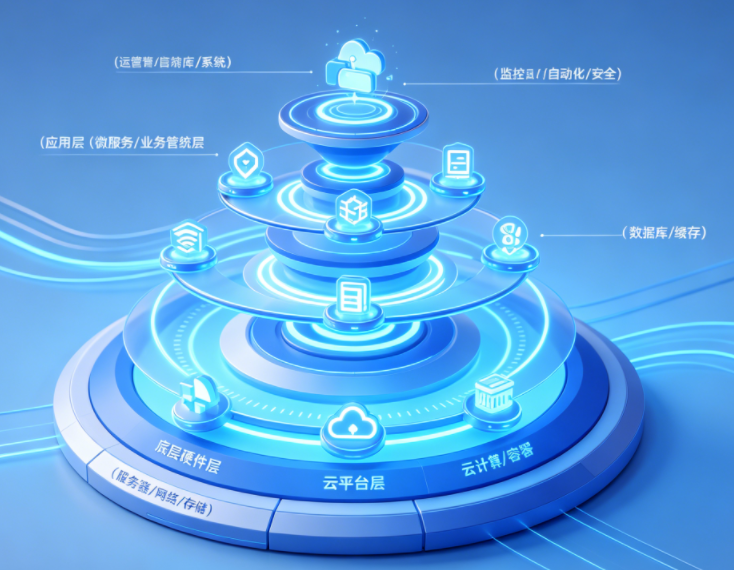
现代IT运维全层级架构体系:从底层硬件、云平台、数据层、应用层到运维管控层,形成全方位立体化运维保障架构,覆盖传统机房架构与云原生容器架构,适配企业全业务场景运维需求。
日常运维工作中,90%以上的业务故障集中在服务器资源过载、网络异常、数据库性能瓶颈、应用服务报错四大场景。本文整理一线实战标准化排查流程,实现故障快速定位、分钟级恢复。
故障现象:业务访问卡顿、接口超时、服务器卡顿、远程连接延迟甚至断开。
核心诱因:CPU使用率过高、内存溢出、磁盘空间占满、磁盘IO过载。
标准化排查步骤:
1. 快速查看整机资源状态:通过top、free、df -h、iostat命令,分别核查CPU、内存、磁盘空间、磁盘IO占用情况,定位异常资源维度;
2. 定位异常进程:针对高占用资源,通过ps、kill命令排查异常进程、僵尸进程,终止无用占用程序;
3. 溯源根因:查看系统日志/var/log/messages,分析资源过载原因,区分是业务流量突增、程序Bug还是资源配置不足;
4. 临时恢复+长期优化:紧急清理磁盘冗余文件、重启异常服务释放资源,后续通过扩容资源、优化程序代码、配置资源阈值预警规避复发。
故障现象:业务访问失败、跨服务器服务调用超时、外网访问不通、内网服务互通异常。
标准化排查步骤:
1. 基础连通性测试:通过ping、telnet测试目标IP和端口连通性,判断是网络不通还是端口未开放;
2. 链路追踪:通过traceroute、mtr排查链路中断节点,定位是内网路由、防火墙拦截还是外网链路故障;
3. 规则核查:检查防火墙策略、安全组白名单、端口映射配置,确认是否存在规则过期、权限限制问题;
4. 网卡状态排查:查看网卡是否丢包、宕机,重启网卡或切换备用链路恢复网络。
故障现象:业务查询缓慢、订单提交超时、数据库连接超时、接口响应延迟飙升。
核心诱因:慢查询堆积、索引失效、数据库连接数打满、缓存击穿、数据表数据量过大。
标准化排查步骤:
1. 抓取慢查询日志,分析低效SQL语句,排查全表扫描、多表联查无索引等问题;
2. 查看数据库连接数、并发数,释放冗余无效连接,调整连接池参数;
3. 核查Redis缓存命中情况,解决缓存失效、热点数据击穿问题;
4. 优化方案:新增索引、拆分大表、优化SQL语句、搭建读写分离架构,从根源提升数据库性能。
故障现象:服务启动失败、接口报错500、服务宕机、微服务调用失败。
排查核心:优先查看应用日志、系统日志、容器日志(Docker/K8s环境),快速定位代码异常、配置文件错误、依赖缺失、端口占用等问题,修正配置、回滚版本、重启服务即可快速恢复业务。

运维故障标准化排查闭环流程:实现故障从发现、定位、修复到复盘优化的全闭环管理,是企业运维标准化、规范化的核心流程,可有效缩短故障处理时长、规避同类问题重复发生。
人工运维的最大弊端是效率低、失误率高、响应慢,自动化运维是现代运维降本增效的核心手段。中小企业可通过轻量化工具组合,快速落地自动化运维体系,无需复杂平台搭建。
1. 监控告警工具:Prometheus + Grafana:开源免费,适配服务器、数据库、应用、容器全维度监控,可自定义CPU、内存、接口响应时间、错误率等监控指标,配置阈值告警,通过企业微信、短信、邮件实时推送故障信息,实现故障事前预警、事中秒级发现。
2. 批量运维工具:Ansible:无需客户端部署,通过SSH协议实现批量服务器命令执行、文件分发、配置更新、软件安装,替代人工逐台操作,大幅提升集群运维效率。
3. 持续部署工具:Jenkins:实现代码自动打包、自动部署、版本回滚,对接代码仓库,开发提交代码后可自动完成部署上线,规避人工部署失误,实现运维部署标准化。
4. 日志分析工具:ELK:集中收集服务器、应用、数据库日志,实现日志统一检索、统计分析、异常日志聚合,解决分布式架构下日志分散、排查困难的问题。
1. 自动化巡检:编写Shell/Python脚本,定时巡检服务器资源、服务状态、端口连通性、数据库状态,自动生成巡检报告,异常状态自动告警,替代人工每日巡检。
2. 自动化备份:配置定时任务,自动备份数据库数据、系统配置文件、业务日志,备份完成后自动校验文件完整性、自动清理过期备份,杜绝人工备份遗漏、备份失效问题。
3. 故障自动恢复:针对常规服务宕机、端口异常等问题,通过监控联动脚本,实现服务异常自动重启、故障自动修复,无需人工介入,缩短业务中断时间。
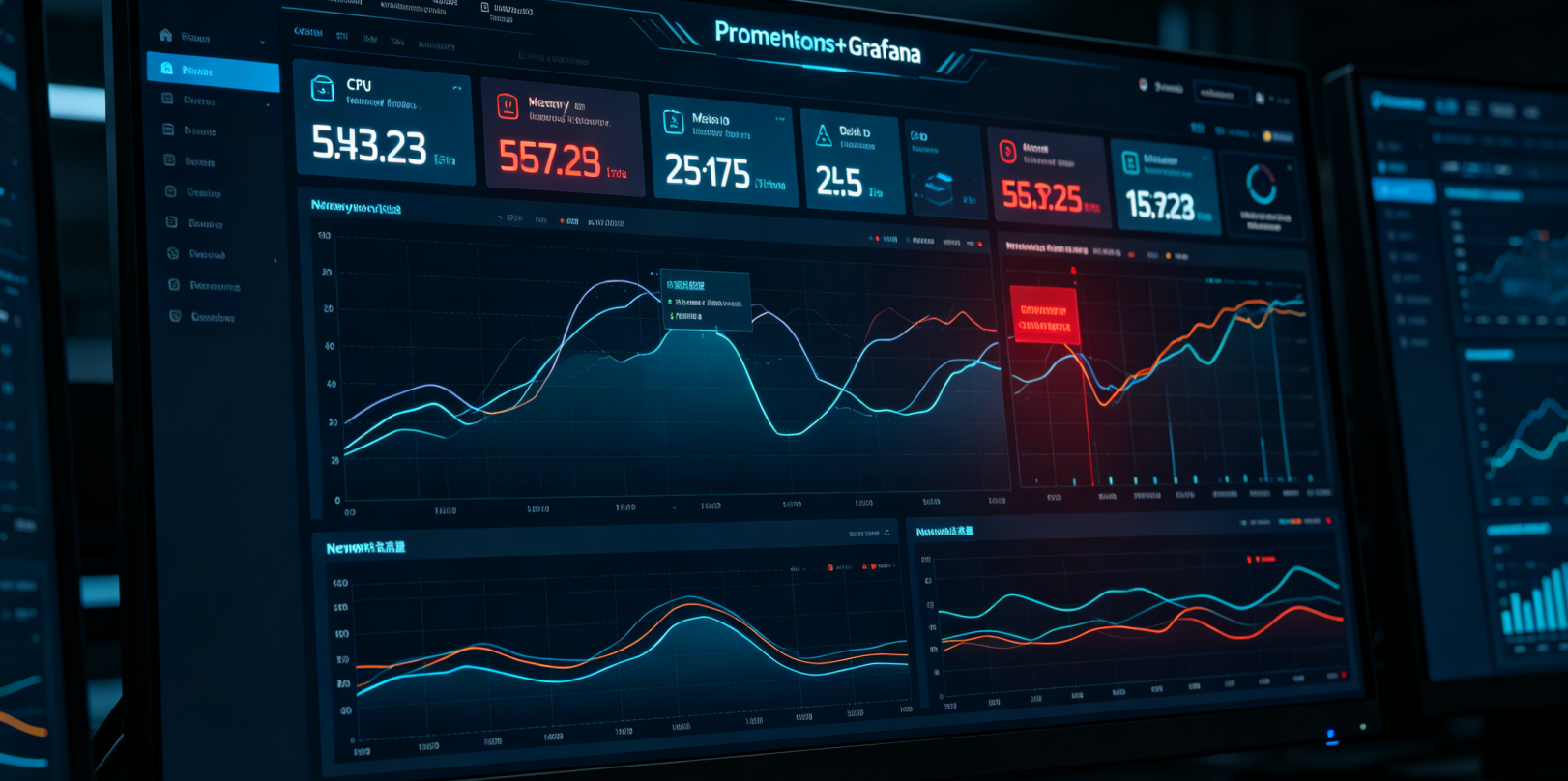
基于Prometheus+Grafana的自动化运维监控面板,实时展示服务器CPU、内存、磁盘IO、网络流量、应用接口指标,支持阈值告警、数据可视化分析,是现代化自动化运维的核心可视化工具。
运维工作的核心目标是保障业务持续稳定运行,在自动化运维的基础上,需配套完善的安全管控和稳定性优化机制,规避各类运维风险。
严格执行最小权限原则,对服务器、数据库、运维平台账号进行分级管控,普通运维人员仅拥有日常操作权限,核心权限(删库、停机、配置修改)专人负责,所有操作全程日志审计,可追溯、可核查,杜绝人为误操作、越权操作风险。
建立完善的数据容灾体系,实现核心数据异地多备份、定时增量备份,同时定期开展故障演练,模拟服务器宕机、数据丢失、网络中断等场景,验证备份可用性和故障恢复能力,避免突发故障时无法恢复业务。
每周开展运维复盘,汇总本周故障问题、操作失误、系统瓶颈,针对性优化监控规则、自动化脚本、系统配置;每月完成服务器漏洞扫描、补丁更新、资源梳理,持续优化系统性能和稳定性。
传统人工运维模式已无法适配数字化业务的发展需求,自动化、智能化、云原生化、业务化是IT运维的核心发展趋势。未来运维人员不再是单纯的“设备管理员”,而是业务稳定性保障师、运维架构优化师。
运维工作将彻底实现三大转型:从被动故障处理转向主动风险预防,从人工重复操作转向全流程自动化运维,从基础设备管控转向业务全链路保障。企业运维团队需持续优化技术体系,落地自动化、智能化运维方案,在降本增效的同时,为业务高速发展提供坚实的IT支撑。
IT运维是企业数字化的幕后核心支撑,系统的运维体系、标准化的故障处理流程、成熟的自动化运维方案,是保障业务高可用、降低运维风险、提升运维效率的关键。一线运维从业者需摒弃传统运维思维,深耕云原生运维、自动化运维技术,通过标准化、流程化、自动化、智能化的运维手段,实现从“救火式运维”到“预防性运维”的升级,助力企业数字化业务稳定、高效、可持续发展。