
随着互联网业务高速迭代,从传统单体网站到分布式微服务、容器云架构,业务规模指数级增长。服务器集群、数据库、中间件、网络、安全、应用服务交织在一起,传统人工救火式运维早已无法支撑业务稳定运行。现代互联网运维正在向着自动化、可视化、可观测、DevOps一体化方向转型。本文结合一线运维实战经验,拆解新一代运维架构,分享故障治理、运维自动化、云平台管控全流程方案。
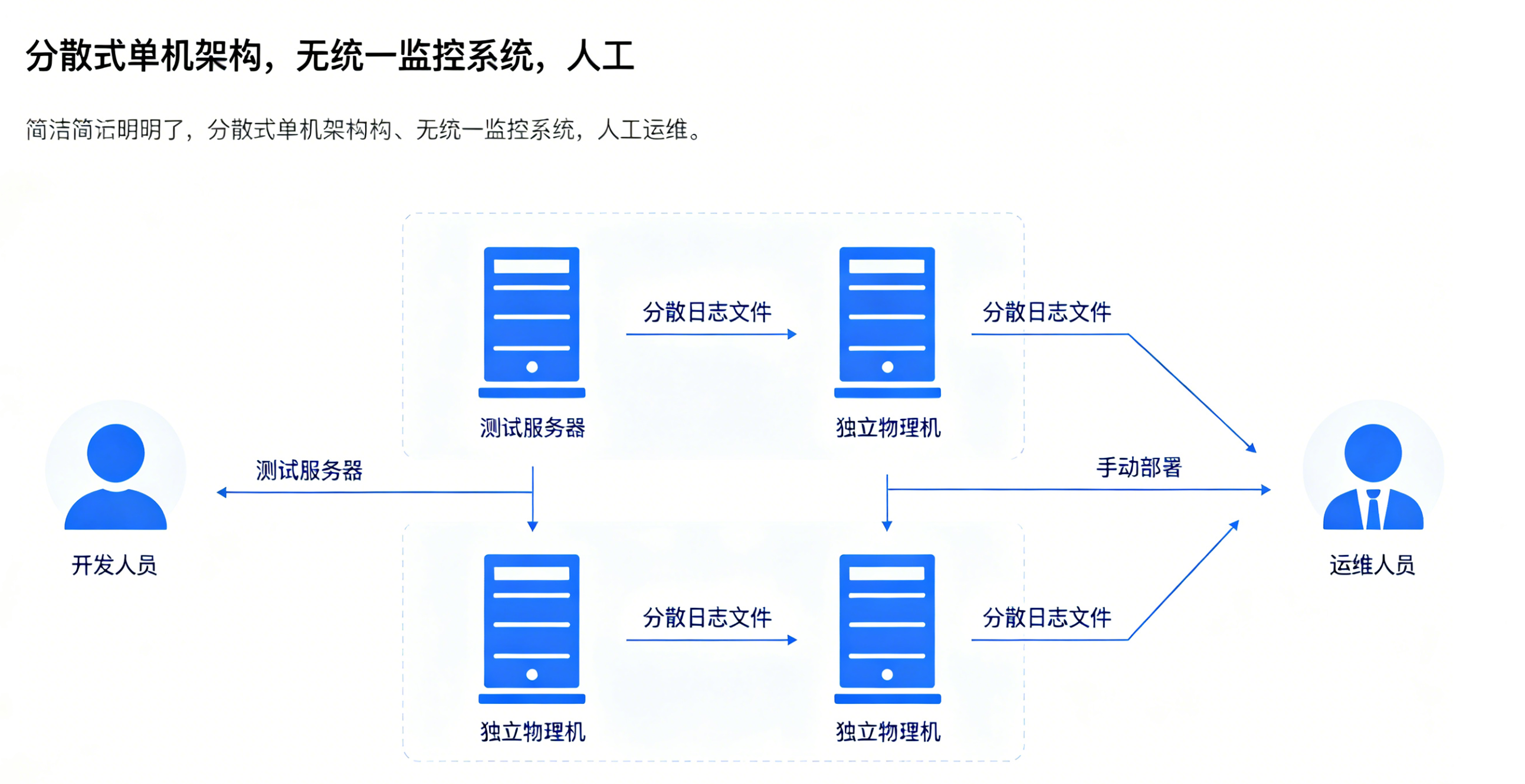
几十上百台服务器依靠SSH逐台登录操作,部署、变更、补丁升级全靠手动敲命令,重复工作量大,效率极低。
业务卡顿、接口超时、数据库死锁发生后,日志分散在几十台节点,没有统一监控平台,只能挨个登录服务器抓取日志,故障定位动辄几十分钟。
开发、测试、生产环境配置差异大,本地运行正常,上线后直接报错,大量时间耗费在环境对齐上。
版本发布、配置修改缺少审批与回滚机制,随意操作极易引发线上事故,且无法追溯操作人。
配图1说明:传统运维架构拓扑图
拓扑内容:开发人员→测试服务器→运维手动部署→多台独立物理机→分散日志文件,无统一监控中心。
整套运维体系分为五大核心模块,也是绝大多数中大型互联网公司的标准建设方案:
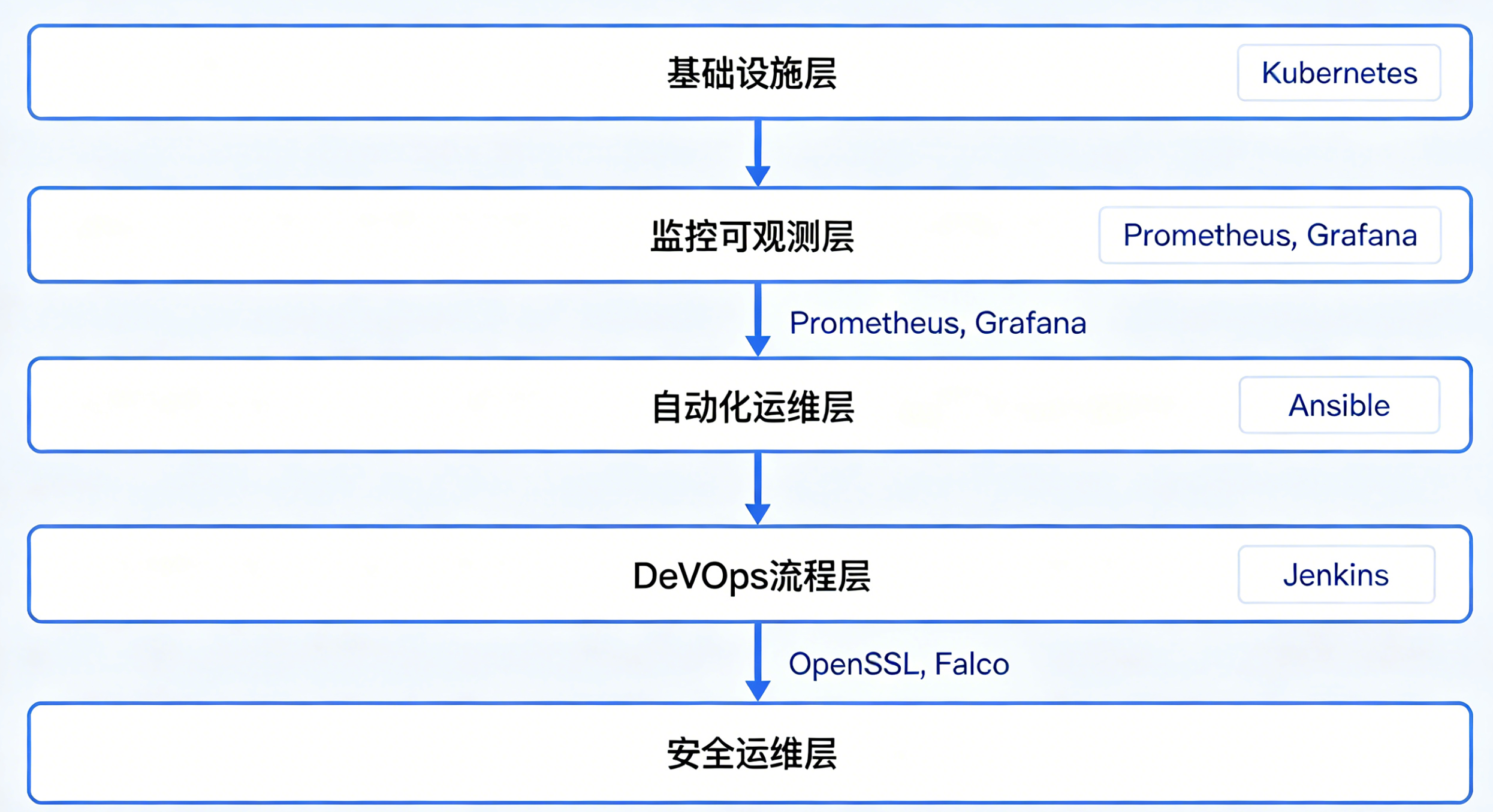
包含公有云ECS、物理服务器、K8s容器集群、负载均衡SLB、对象存储OSS、CDN、Redis集群、MySQL主从集群、网络防火墙。
三大支柱:指标监控、日志收集、链路追踪。
主流技术栈:
- 指标监控:Prometheus + Grafana + AlertManager
- 日志系统:ELK(Elasticsearch+Logstash+Kibana)
- 链路追踪:SkyWalking / Jaeger
作用:全覆盖采集服务器CPU、内存、磁盘IO、网络流量、应用接口耗时、SQL执行效率,一旦指标异常自动触发短信、钉钉告警。
核心目标:解放双手,消除人为操作失误。
工具栈:Ansible批量执行、Jenkins持续发布、Docker容器打包、Kubernetes容器编排。
实现:一键部署应用、批量修改配置、定时清理磁盘、自动扩容缩容。
打通代码提交→自动构建→自动化测试→镜像打包→灰度发布→线上监控整条流水线。
配套工具:Gitlab、SonarQube代码质量检测、Harbor镜像仓库。
堡垒机权限管控、操作日志审计、漏洞扫描、端口防护、数据库权限隔离,杜绝越权操作与黑客入侵。
配图2说明:自上而下五层模块,模块之间用箭头串联数据流,标注对应开源工具名称
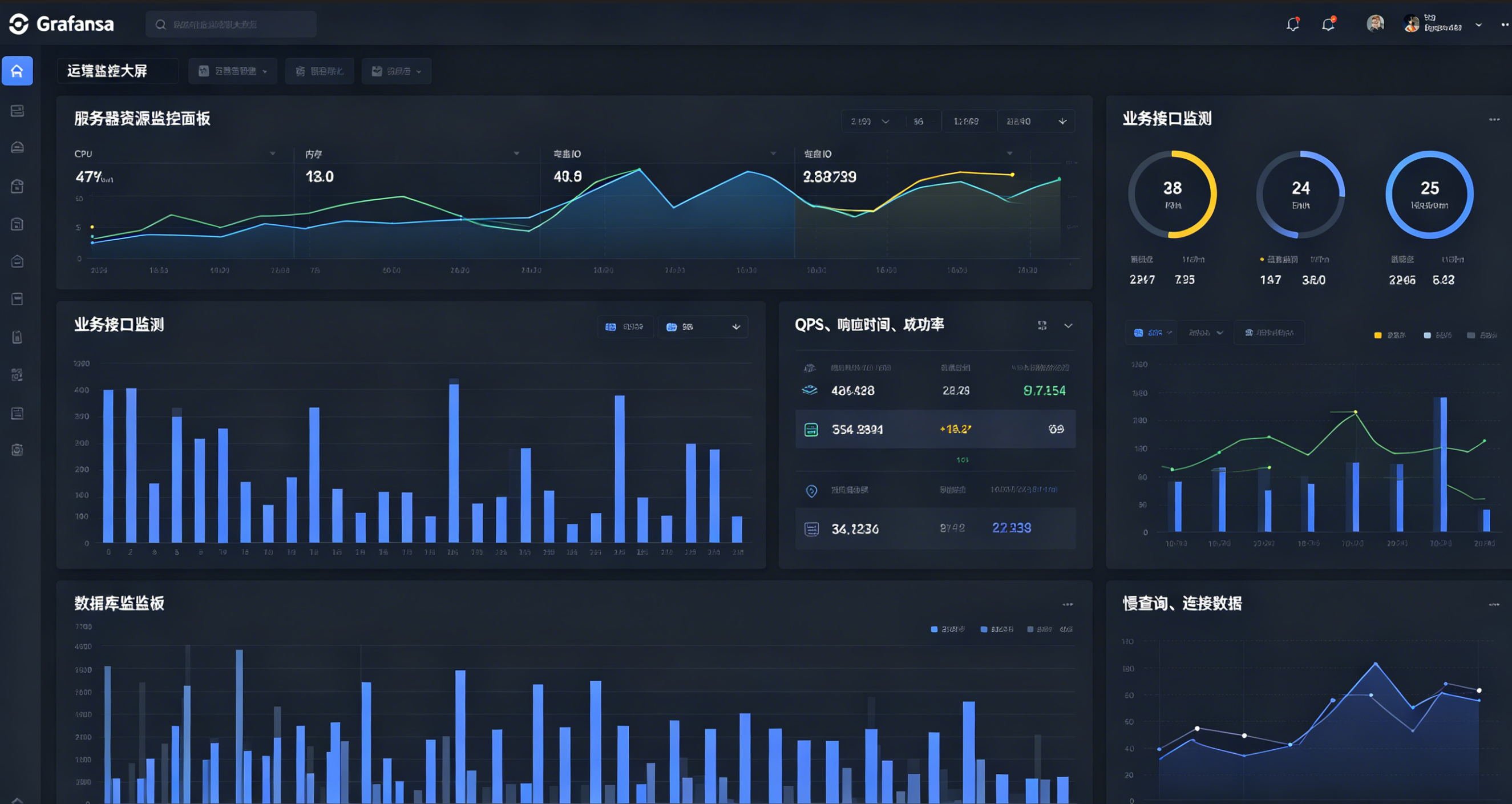
通过Node-Exporter采集所有服务器硬件资源指标,Grafana绘制可视化大屏。
监控指标清单:CPU使用率、空闲内存、磁盘使用率、inode占用、网卡出入流量、系统负载。
设置阈值告警:磁盘使用率超过85%立即推送钉钉告警,提前规避磁盘爆满宕机问题。
- 业务接口:QPS请求量、成功率、平均响应时间、异常报错数
- MySQL:慢查询、连接数、主从延迟、锁等待、事务回滚量
- Redis:命中率、内存占用、键过期数量
配图3说明:包含服务器资源面板+业务接口面板+数据库面板可视化大屏
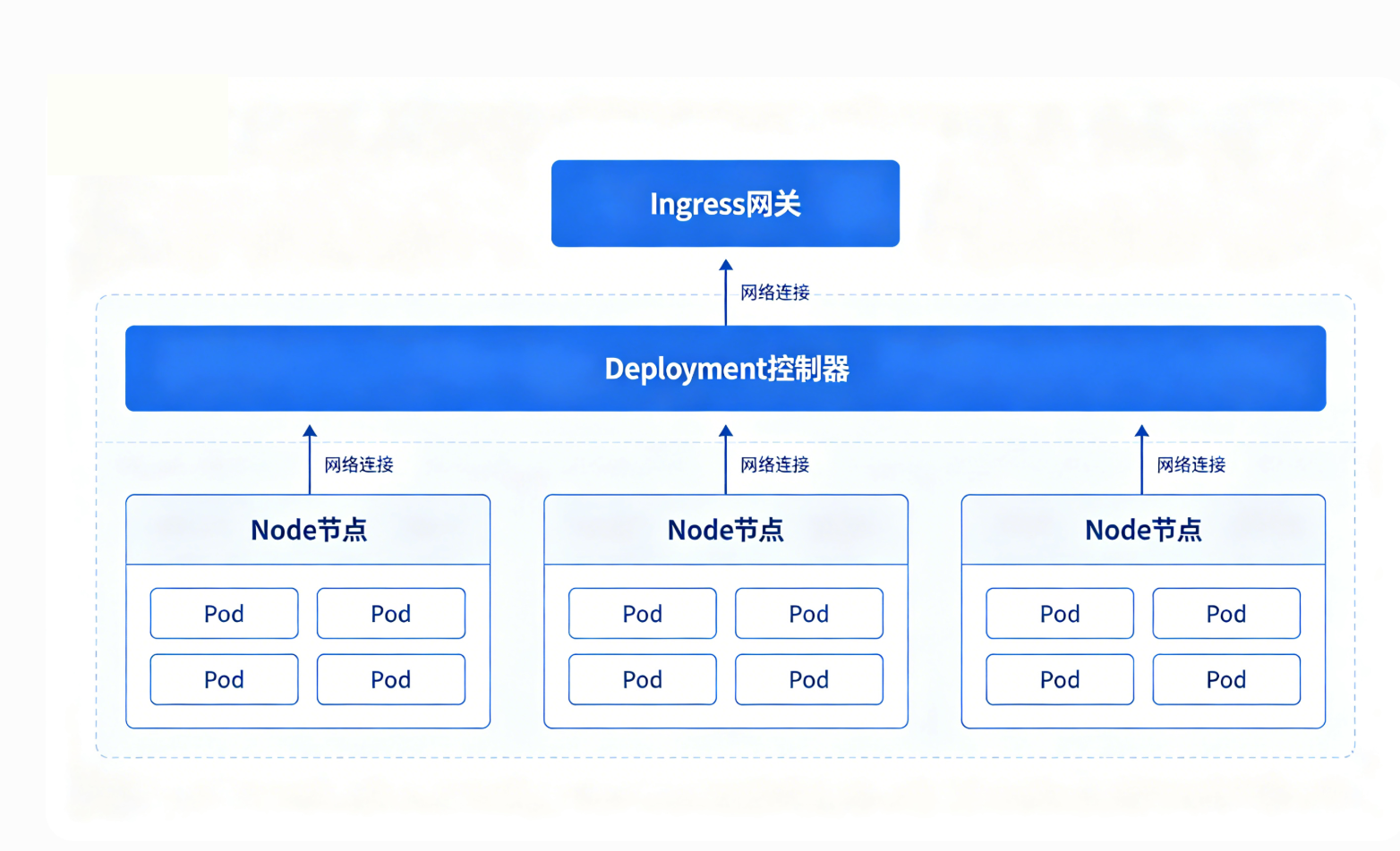
互联网业务流量波动极大,电商、短视频项目高峰期流量暴涨,低谷资源闲置。传统固定服务器资源浪费严重,K8s可以实现弹性伸缩:
1. 业务流量上涨,自动新增Pod实例承接流量;
2. 业务低谷自动释放多余实例,节约云服务器成本;
3. 版本支持灰度发布、滚动更新,新版本异常自动回滚,保障线上零停机更新。
配套组件:Ingress网关、CoreDNS服务发现、Metrics弹性伸缩组件。
配图4说明:K8s节点、Pod、控制器、网关组件完整拓扑结构图
上千台服务器统一管理,无需逐台登录:
- 批量推送配置文件
- 批量执行系统命令
- 批量安装服务、升级系统补丁
所有操作留存执行日志,做到每一次变更都有据可查,满足企业内控要求。
配图5说明:Ansible批量任务执行结果、日志输出后台界面
运维不只是保障服务正常运行,更要不断降低事故发生率。
- P0(核心故障):全站无法访问、支付服务瘫痪,5分钟内必须响应处理;
- P1(一般故障):个别接口报错,非核心功能异常,30分钟内处理完毕;
- P2(预警信息):资源即将不足、少量慢SQL,工作时段优化即可。
针对宕机、数据库崩溃、带宽打满、CDN故障编写预案,定期组织演练,避免突发故障手忙脚乱。
每一次线上事故输出复盘报告:故障根因、影响时长、临时解决方案、长期优化措施,避免同类问题重复发生。
现象:凌晨业务突然大量超时,服务器CPU满载。
排查流程:监控查看→定位到数据库大量慢查询→找到未加索引的SQL→临时优化语句→后续给字段建立索引,同时开启SQL审计拦截低效语句。

利用人工智能自动分析海量监控数据,自动识别异常波动,告别人工配置告警阈值,系统自动预测资源瓶颈,提前规避故障。
所有业务容器化,全面拥抱公有云+混合云架构,运维从管理物理机器转向管理集群与应用。
运维工程师深入参与研发流程,从源头优化架构,而不仅仅是被动处理线上故障,SRE站点可靠性工程师成为互联网大厂主流岗位。
使用Terraform代码管理云资源,服务器、数据库、网络全部通过代码创建销毁,环境100%标准化。
配图6说明:AIOps异常智能识别、资源预测、智能告警平台界面示意图
互联网运维早已告别“网管”时代,从被动救火转向主动保障。一套完善的运维体系=统一监控+自动化发布+容器云底座+故障治理+权限安全。
中小团队可以先搭建ELK+Prometheus基础监控,再落地Jenkins自动化发布;中大型企业逐步搭建完整K8s集群与DevOps流水线,最终向智能运维AIOps演进。稳定可靠的基础设施,才是互联网业务持续高速发展的基石。